
Option 2: Scan and Match Data
Updated over a week ago
The second method for mapping incoming, yet-to-be-mapped RestaurantologyLog records to existing Salesforce Accounts is using “Scan and Match Data”, which works with normalized Name and Website data to heighten accuracy at scale.
The goal of Scan and Match Data is to create a cached version of your Account data that allows admins to heavily filter data and map (or create) only the Accounts they find of interest at a particular moment in time.
Along with Data Matching Helper, Scan and Match Data should likely be considered the second of two (2) primary means of connecting data during both the implementation phase of Restaurantology, as well as when reviewing ongoing additions of new data month over month.
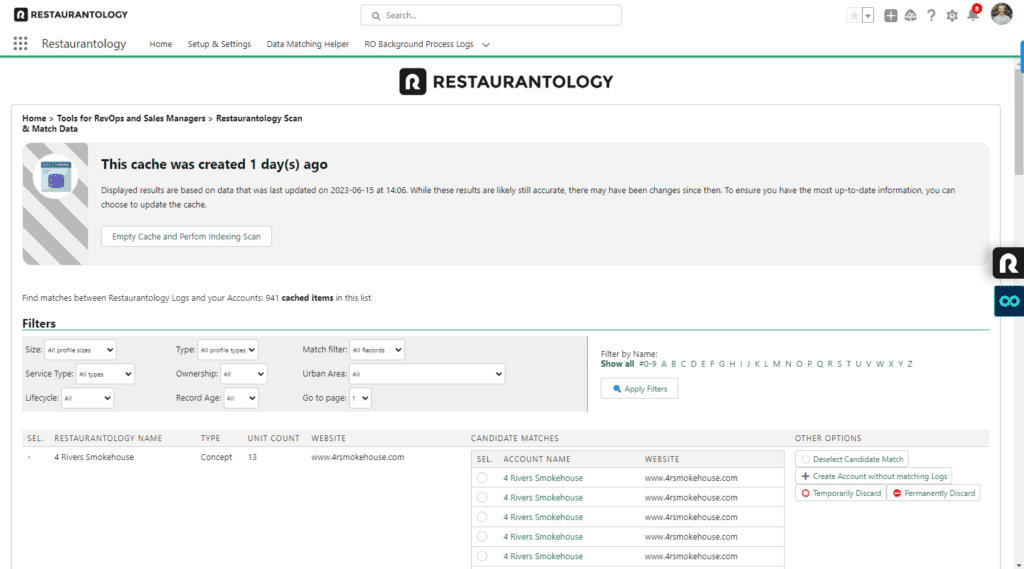
Accessing Scan and Match Data
Scan and Match Data is found in the Salesforce App Center, which can be accessed by clicking the 9 dots in the upper left-hand portion of your Salesforce production instance. From the dropdown, type “Restaurantology” and choose the App.
Note: Users who intend to use Scan and Match Data will need to ensure they have the proper access, profile, and permission to interact with the mapping tool. Users who are unable to access the App Center or who cannot match or create Account records with RestaurantologyLogs should contact their system administrator.
Creating and refreshing cache
Prior to initial use of Scan and Match Data, you will be prompted—and ultimately required—to create a cache of your existing, unmapped Account data. Data caching is required for two primary reasons: to normalize unformatted data, which increases Restaurantology’s ability to recommend candidate matches, and to allow advanced filters to be applied across hundreds or thousands of records with real-time results.
The caching process can take up to five (5) hours, and is directly influenced by the size of your Account list in your Salesforce org. We recommend that whenever possible you initiate your cache well in advance of when you intend to begin mapping data.
Caches can be emptied and refreshed at any given time, and are typically considered when any of the following take place:
- New/updated RestaurantologyLogs need to be considered;
- New mass-important, or rep-generated, Accounts need to be considered;
- Past temporarily-discarded records need to be (re)considered.
Remember: Both Restaurantology insights and your Salesforce Account data are changing constantly and, thus, you should consider refreshing your Scan and Match Data cache frequently.
Lastly, users can track the progress of your data caching indexing scan at any time by referring to the scan’s progress bar.
Using advanced filters
Scan and Match Data offers admins the use of advanced filters as they navigate through their cached data. In addition to the 4 filters shared with Data Mapping Help (Size, Record Type, Record Age, and Letter), Scan and Match Data also includes filters for:
- Record Matches – Isolate entries with candidate matches from those where no similar existing Account is detected.
- Service Type – Isolate Full-Service and Limited-Service entries.
- Ownership – Isolate records that are known to have a parent.
- Urban Area – Isolate records that are found withing a prevalent urban area.
- Lifecycle – Isolate records by any of the existing six inferred status options.
Reviewing candidate matches
Similar to the Data Matching Helper, Scan and Match Data allows to review candidate matches in instances where an existing Salesforce Account has a high similarity to an unmatched multi-unit RestaurantologyLog record. Comparisons are made using the Levenshtein distance between normalized Account Name and Restaurantology Name fields, as well as normalized Account Website and Restaurantology Website fields.
Candidate matches do not only result from exact-match fields. Users reviewing candidate matches should review each recommendation before either mapping the records or deciding to create a net-new Account.
Some RestaurantologyLog records may have up to 10 (or more) candidate matches, particularly in instances where similarly-named Accounts exist. We recommend users exercise caution, however you should also note that improperly matched records can always be manually mapped to a new record using the Visualforce component on the Account page layout.
Creating new Accounts
Some RestaurantologyLog records may not have a candidate match. This could result from [01] no existing Account sharing similar Name and Website data, or [02] an existing Account has data that is too different from the expected values to be recommended as a candidate match.
New Accounts can be created and instantly mapped to the unmatched RestaurantologyLogs both individually and in bulk using the “Create Account” buttons either next to each entry, or at the bottom of the page for any record(s) with the checkbox selected.
Discarding records
Scan and Match Data allows certain Restaurantology records to be either temporarily or permanently discarded. To learn more about to discard records, read on here.
Pros and cons when using Scan and Match Data
There are certain instances when Scan and Match data is both recommended and prioritized, however it’s important to know why certain features are not available in this particular widget.
Pros
- Candidate matches are based on a higher-tolerance fuzzy match between the respective Name and Website fields.
- Advanced filters allow users to created the portion of new Accounts that are most meaningful to the business.
- Caching data allows users to focus on a single set of non-changing data (Data Matching Helper will consider new entries and is therefore constantly changing) to complete their intended project.
- Lower priority records can be temporarily or permanently discarded.
Cons
- Any changes outside the existing cache are not considered until a subsequent cache is performed. This includes new/updated Restaurantology records, as well as new/updated Account data.
- Similar to the Data Matching Helper, Scan and Match Data is also subject to the 2,000 query governor limit, however it is significantly harder to hit this limit.
- Caching data requires a set amount of lead time, and in certain instances can take up to 5 hours to complete in the background.